
Published
- 15 min de lectura
Turborepo de Go a Rust, II

Traducido de la entrada de Nicholas Yang del Core Team de Turborepo en el blog de Vercel.
Hemos estado trasladando Turborepo, el sistema de construcción de alto rendimiento para JavaScript y TypeScript, de Go a Rust. Hablamos sobre cómo comenzamos el proceso de traslado, así que ahora hablemos sobre cómo comenzamos a trasladar nuestros dos comandos principales: run y prune.
Desde la última vez
Cuando nos quedamos la última vez, habíamos comenzado nuestro traslado implementando el turbo global y el análisis de argumentos de línea de comandos en Rust. Debido a problemas relacionados con la vinculación estática y la incompatibilidad de Go con musl, un requisito esencial para la compatibilidad con Alpine Linux, dividimos Turborepo en dos binarios: uno en Rust y otro en Go.
Después de eso, trasladamos los comandos auxiliares como login, link, unlink. Estos fueron bastante simples de trasladar ya que solo requerían un cliente HTTP básico y algo de gestión de configuración. Pudimos trasladarlos en una o dos pull requests a la vez.
run y prune
Sin embargo, después de estos comandos, nos enfrentamos a un problema: ¿cómo podríamos trasladar run y prune? run y prune son los comandos que realizan la mayor parte del trabajo en turbo. run, bueno, ejecuta tus tareas, como build, lint y test. prune toma tu Turborepo y produce un subconjunto que solo contiene un paquete y sus dependencias. Esto es útil cuando quieres usar solo un paquete específico, como en un contenedor Docker, y no quieres copiar todo el Turborepo en el contenedor.
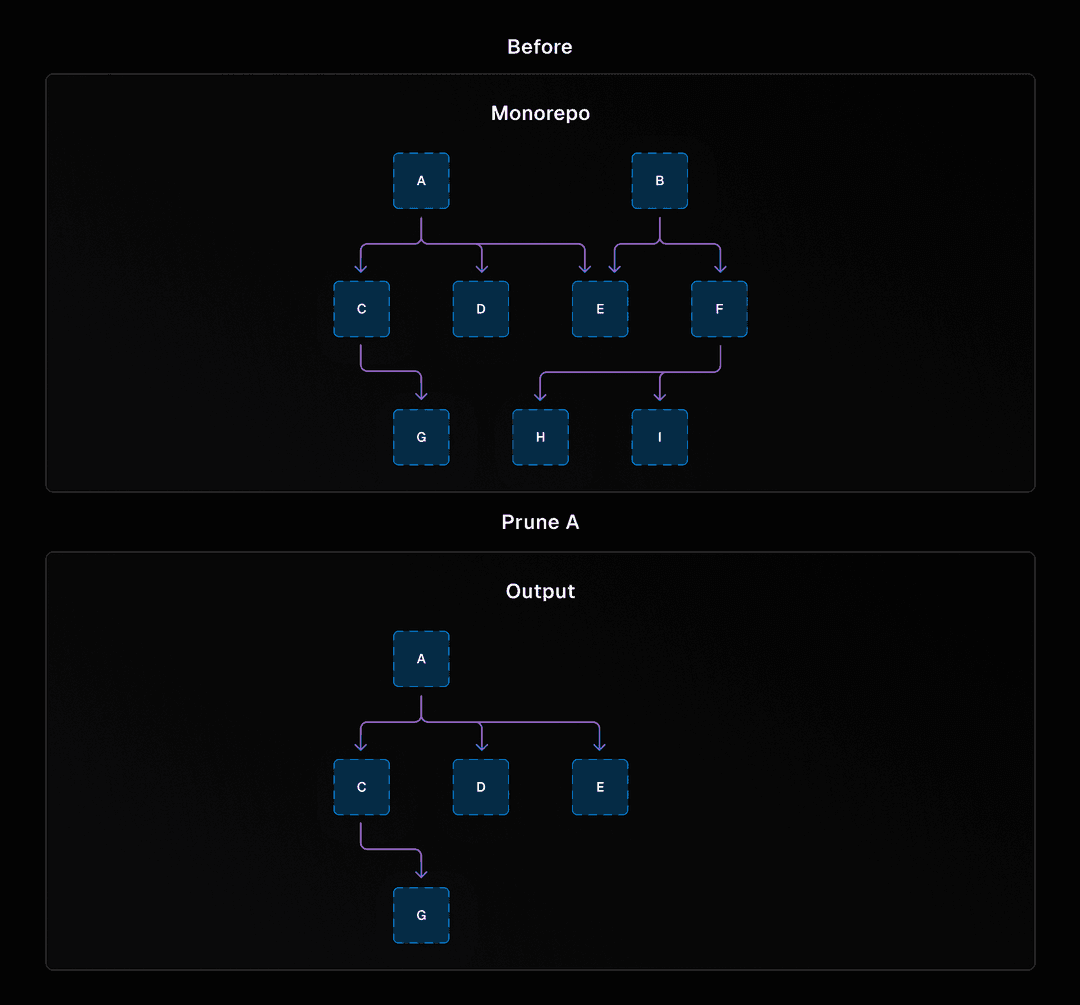
Un gráfico que muestra un monorepo completo con paquetes abstractos, y otro gráfico dirigido que muestra un subconjunto del monorepo después de ejecutar turbo prune en el monorepo.
Como tales, son fragmentos de código bastante grandes. Por ejemplo, run hace lo siguiente:
- Procesa la configuración de los argumentos de línea de comandos, tus archivos turbo.json, variables de entorno, etc.
- Inicia un gráfico de dependencias de los diversos paquetes en tu Turborepo, es decir, el gráfico de paquetes. Determina qué paquetes han sido modificados.
- Descifra qué tareas deben ejecutarse y en qué orden, utilizando un gráfico de dependencias de tareas, es decir, el Gráfico de Tareas.
- Ejecuta las tareas en paralelo.
- Guarda las salidas de estas tareas en la caché del sistema de archivos y/o la caché remota.
- Produce un resumen de esta ejecución.
¡Y esta es una versión simplificada y de alto nivel! En realidad, hay mucho más sucediendo, como filtrado, ejecuciones en seco, hashing, y más. No pudimos mover estos comandos en una o dos pull requests como podríamos hacerlo con los comandos de autenticación anteriormente. Necesitábamos una manera de moverlos de forma incremental.
Estrategias para la migración incremental
Consideramos algunas estrategias para trasladar run y prune a Rust, todas basadas en principios de migración incremental.
Opción 1: La misma estrategia
La primera estrategia que consideramos fue continuar con lo que ya estábamos haciendo para el análisis de la línea de comandos: hacer más trabajo en el código Rust y pasar el resultado al código Go. Sin embargo, esto tenía un fallo fatal. Casi todo el trabajo que estábamos haciendo en run involucraba el gráfico de dependencias de paquetes o el gráfico de dependencias de tareas. Los gráficos pueden volverse grandes extremadamente rápido, por lo que serializarlos sobre JSON induciría mucho sobrecarga.
Además, desde una perspectiva de estabilidad, el gráfico de paquetes es la abstracción central dentro de turbo. Necesitábamos construir suficiente infraestructura y pruebas para asegurarnos de que fuera sólida como una roca antes de poder enviar una versión trasladada.
Opción 2: Escribir desde cero
Otra opción sería construir una versión en Rust de run/prune desde cero, y luego cambiar una vez que esté completa. No queríamos hacer esto, ya que, como se indicó en la publicación de blog anterior, no estábamos seguros de poder producir una reescritura completa que mantuviera el mismo comportamiento.
Opción 3: Trampolín
También tuvimos algunas ideas que implicaban reutilizar nuestra infraestructura existente, como crear un trampolín donde el binario de Go tendría una función de punto de entrada que podría redirigir a diferentes partes del pipeline de run, para que el código Rust pudiera llamar al binario de Go, obtener un resultado, procesarlo más y luego llamar al binario de Go nuevamente. Esto nos permitiría reutilizar la configuración de los dos binarios que ya teníamos. Si estás familiarizado con los callbacks de JavaScript, puedes pensar en esto como el código Rust que produce eventos que el código Go maneja con un callback.
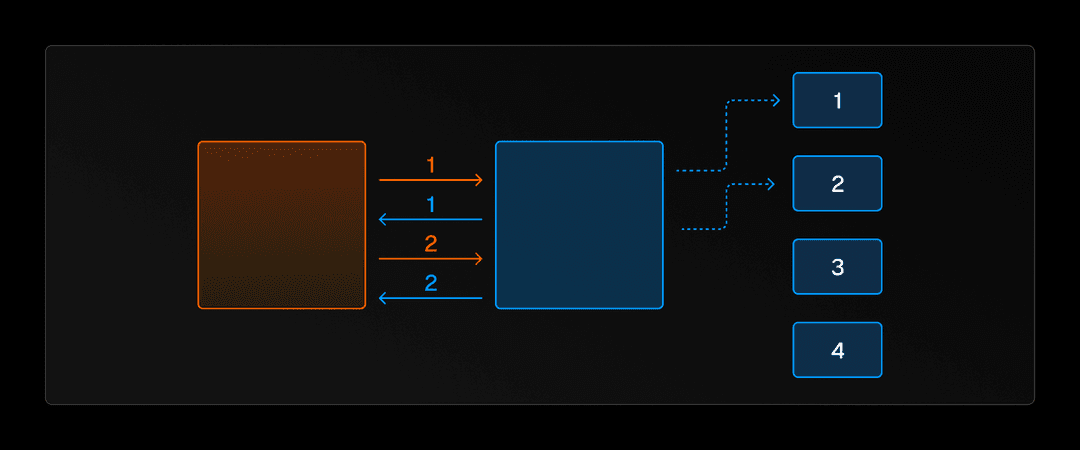
Opción 4: Utilizar el daemon (servicio)
De manera similar a la opción anterior, consideramos adaptar el daemon de Turborepo para el traslado. El daemon es una optimización de rendimiento que se ejecuta en segundo plano y observa los archivos en tu Turborepo. De esta manera, cuando ejecutas una tarea, turbo ya sabe qué archivos han cambiado y, por lo tanto, qué tareas ejecutar. Nuestra estrategia sería trasladar el daemon a Rust, y luego agregar más y más funcionalidad al daemon, como hacer que cree el gráfico de paquetes y el gráfico de tareas. Sin embargo, el daemon está destinado como una mejora de rendimiento opcional, por lo que hacerlo una parte esencial del pipeline de run sería un cambio significativo en la arquitectura.
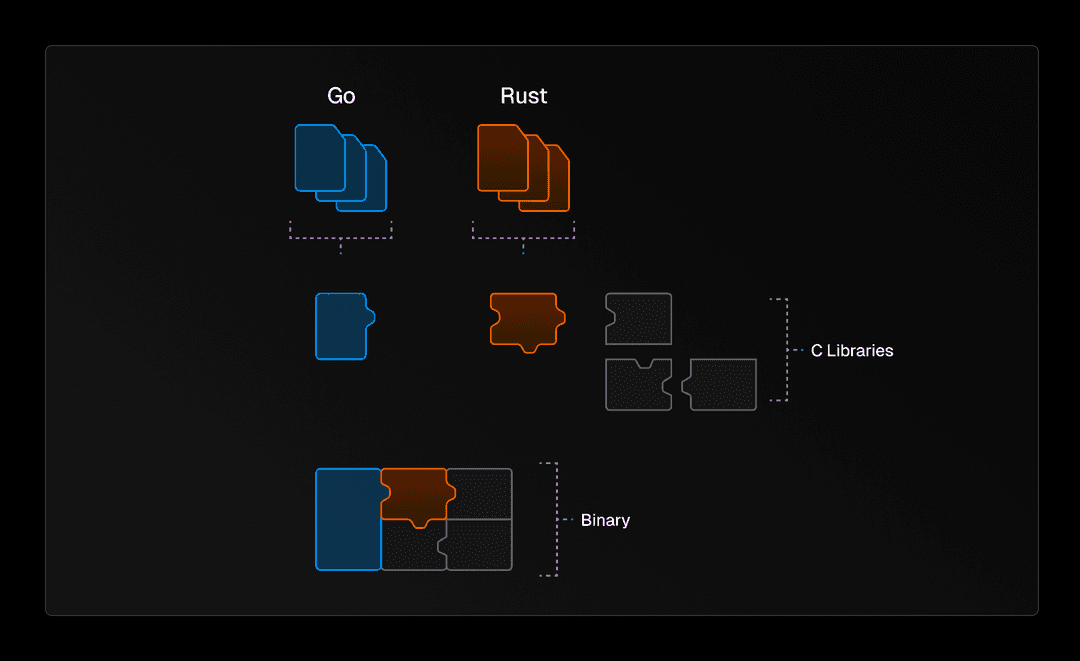
La solución ganadora: El sándwich Go
Después de considerar estas opciones, optamos por construir lo que llamamos el “sándwich de Rust-Go-Rust” o el “sándwich de Go” para abreviar. Consiste en un binario Rust que llama a un binario Go, que a su vez llama a bibliotecas Rust que están enlazadas estáticamente en el binario Go. Esto nos permite dividir el código de run y prune entre los dos lenguajes y trasladar dependencias individuales. De esta manera, pudimos abordar el run y el prune de manera incremental, permitiendo una mejor prueba y depuración a través de la migración.
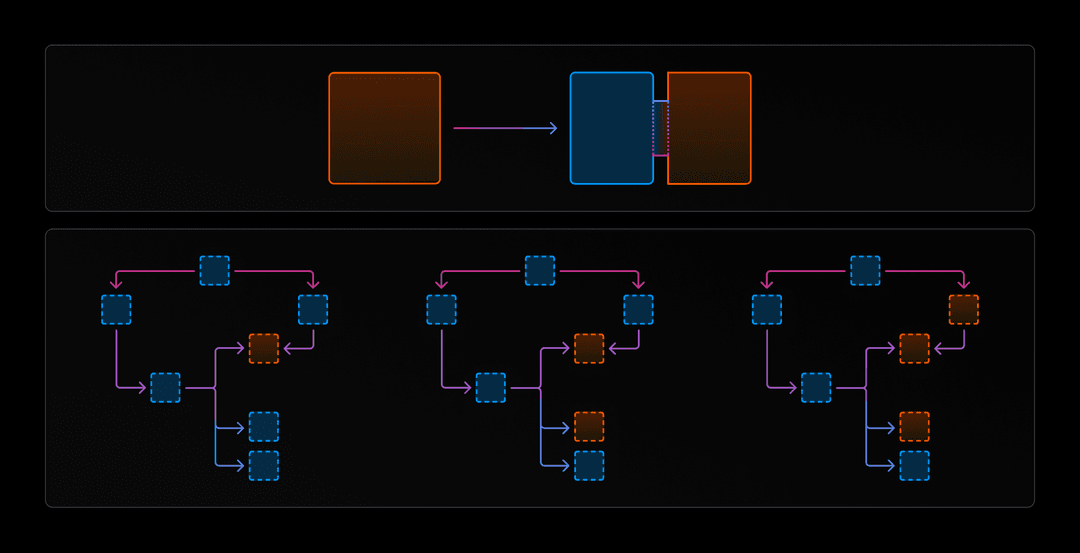
Las dependencias de Rust que hemos trasladado están contenidas en la crate turborepo-ffi. Compilamos esa caja a una biblioteca estática C (un staticlib en términos de Rust). A partir de ahí, la vinculamos a nuestro binario de Go usando CGO. A diferencia de la última vez, no nos encontramos con problemas de segmentación porque, mientras que la vinculación de Go a Rust está rota con musl, la vinculación de Rust a Go está bien.
Para comunicarnos entre Go y Rust, decidimos usar protobuf, ya que era independiente de la plataforma, relativamente compacto y tenía un esquema explícito que podía ser utilizado para generar tipos en Rust y Go, manteniendo nuestros tipos sincronizados entre los lenguajes. Esto fue especialmente importante ya que teníamos mucha más superficie de contacto entre Rust y Go que cuando estábamos trasladando los argumentos de la línea de comandos.
Finalmente, modificamos nuestro proceso de construcción para que pudiéramos activar o desactivar el sándwich Go según sea necesario. De esta manera, siempre podríamos revertir al código de Go si encontrábamos errores en la implementación de Rust. Esto significaba que teníamos que mantener el código de Go, pero sabíamos que esto era temporal en última instancia.
Proceso de traslado en forma de sándwich
Vamos a repasar un ejemplo de traslado a Rust. Tenemos código para incluir variables de entorno en lo que llamamos nuestro hash global, que determina si tenemos un cambio global que requiere volver a ejecutar todas nuestras tareas. Este es un fragmento de código agradable y autocontenido, por lo que fue un buen candidato para el traslado.
Para empezar, necesitábamos determinar exactamente qué queríamos trasladar. Idealmente, deberíamos trasladar fragmentos no triviales, ya que no queremos inducir la sobrecarga de protobuf para una función trivial, pero no debería ser tan grande que esté fuera del alcance de una sola solicitud de extracción. En este caso, decidimos trasladar la función getGlobalHashableEnvVars, que toma la configuración de las variables de entorno del usuario y determina qué variables de entorno proporcionar como entradas al hash global.
A continuación, dividimos el código existente en la antigua implementación de Go (global_hash_go.go) y el nuevo código de Go que llama a la implementación de Rust (global_hash_rust.go). Usamos tags de compilación de Go para decidir qué implementación construir para que siempre podamos volver a la antigua implementación de Go si la nueva implementación de Rust contiene un error.
Luego, escribimos la implementación de Rust, agregamos los tipos de entrada y salida necesarios a nuestro esquema de protobuf, creamos una función exportada en turborepo-ffi y llamamos a esa función en ffi.go. ¡Y por supuesto, nos aseguramos de escribir pruebas! Si deseas ver el proceso completo, puedes encontrar la pull request aquí.
Con toda esta configuración, pudimos trasladar más y más piezas de run y prune a Rust en un proceso relativamente sencillo. Sin embargo, cuando llegó el momento de enviar el sándwich de Go, nos encontramos con algunos problemas de lanzamiento. Así es cómo los resolvimos con un aliado poco probable.
El proceso de lanzamiento de Turborepo
Turborepo se distribuye como un binario nativo en Windows, Linux y macOS para ambos x86-64 y aarch64, las dos arquitecturas de CPU predominantes. Haciendo los cálculos, eso son 6 objetivos para construir y soportar, no es una tarea fácil. Como detallamos en nuestra publicación sobre por qué estamos pasando de Go a Rust, es bastante difícil escribir código que maneje características de bajo nivel como sistemas de archivos y procesos de manera multiplataforma. Sin embargo, lo que es más desafiante es construir y lanzar este código multiplataforma para 6 objetivos diferentes, especialmente cuando se están utilizando dos lenguajes diferentes con dos cadenas de herramientas diferentes.
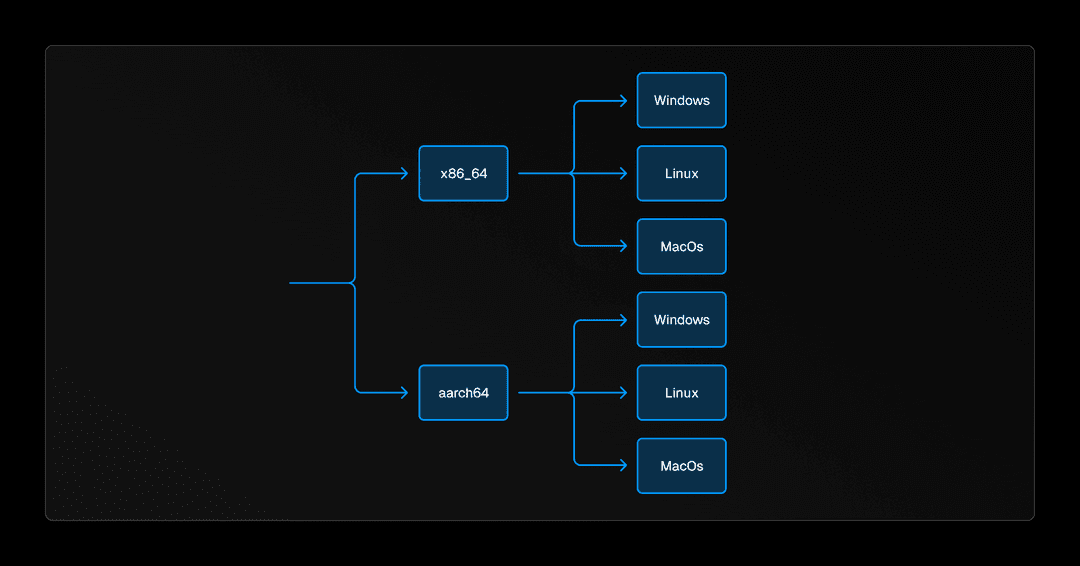
Generalmente, cuando escribes código y lo compilas, estás realizando una compilación nativa. Estás construyendo el código para el sistema operativo y la arquitectura de la computadora que estás utilizando actualmente. Esto funciona muy bien para el desarrollo local; compilas y ejecutas inmediatamente en tu computadora. Pero para las versiones, este proceso necesita cambiar. No podemos crear 6 máquinas diferentes para cada uno de los objetivos que soportamos. Tomaría mucho tiempo y desperdiciaría recursos informáticos, y nuestra tubería de lanzamiento está en GitHub Actions, que de todos modos no admite aarch64.
En cambio, hacemos lo que se llama una compilación cruzada. La compilación cruzada implica construir tu código para un sistema operativo y/o arquitectura que no es la misma que la de la computadora que estás utilizando actualmente. Por ejemplo, puedes compilar de forma cruzada un binario Linux x86-64 en una computadora macOS aarch64.
Para manejar la compilación cruzada para nuestro código de Go, usamos una herramienta llamada Go Releaser. Como su nombre lo indica, Go Releaser libera código de Go construyendo binarios para múltiples objetivos, y luego los libera (en nuestro caso a npm).
Complicaciones del sándwich de Go
Con el sándwich de Go, tuvimos un nuevo problema: ¿cómo podemos liberar un binario híbrido Go-Rust?
Habíamos diseñado nuestro sándwich de Go para usar una caja de Rust, turborepo-ffi, compilada a un staticlib, una biblioteca C nativa, que luego vinculamos a nuestro código de Go a través de CGO. Esto funcionó muy bien localmente. Sin embargo, cuando se trató de lanzarlo, nos encontramos con algunos problemas.
Windows ARM
Como recordarás del último post, hay dos principales cadenas de herramientas con Windows: Microsoft Visual C++ (MSVC) y Minimalist GNU for Windows (MinGW). La primera, MSVC, está escrita y mantenida por Microsoft con una Interfaz Binaria de Aplicaciones (ABI) específica, mientras que la segunda, MinGW, porta el conjunto de software GNU a Windows. MinGW tiene su propia ABI, lo que significa que las cosas compiladas para MSVC y para MinGW no son interoperables.
Desafortunadamente, Go solo utiliza MinGW, mientras que Rust solo tiene soporte para MSVC en ARM. Esto significaba que no podíamos vincular los dos lenguajes. Afortunadamente, Windows en ARM viene con emulación x86-64, por lo que podríamos lanzar un binario x86-64 para Windows y dejar que el sistema operativo haga su magia para que se ejecute en ARM. Hay un impacto en el rendimiento asociado, pero solo hasta que lleguemos a un binario de Rust completo, o Rust lance un objetivo ARM de MinGW.
Dependencias de C
El segundo desafío surgió al usar dependencias de C dentro de nuestro código Rust. El proceso de compilación nativa típicamente involucra a los compiladores creando archivos de objeto, que luego se vinculan, o se combinan, para formar un binario. Sin embargo, en nuestro caso, turborepo-ffi se compila en un archivo de objeto, no en un binario. Como resultado, no puede vincular directamente sus propias dependencias de C.
Tomemos zlib como ejemplo. Si turborepo-ffi usa zlib como una dependencia de C, no vincula directamente zlib dentro de su propio archivo de objeto. En cambio, espera que cuando integres turborepo-ffi en un binario (en este caso, el binario de Go) también le suministres un archivo de objeto que contenga la versión compilada de zlib. Esta expectativa surge del hecho de que las bibliotecas estáticas de C no son entidades independientes, sino que están diseñadas para ser entradas a un vinculador, sirviendo como bloques de construcción en la creación de un binario.
De acuerdo, entendido, no usemos dependencias de C en turborepo-ffi. Bueno, eso no es tan fácil. Muchas bibliotecas como git2 y openssl utilizan dependencias de C. ¡Incluso Rust mismo usa dependencias de C! Para manejar el desenrollado de la pila después de un pánico, Rust utiliza una biblioteca llamada libunwind. No hay escapatoria de C, no importa lo mucho que lo intentes.
Como hemos enfatizado antes, todo esto es mucho más simple con la compilación nativa. O bien, las bibliotecas precompiladas ya están instaladas en tu computadora, o son fácilmente instalables con tu gestor de paquetes del sistema (apt-get, brew, apk, etc.).
Con la compilación cruzada, todo esto se va por la ventana. No puedes instalar fácilmente bibliotecas precompiladas para plataformas diferentes a la tuya nativa. Puedes compilar desde el código fuente (¡más compilación cruzada!), pero los compiladores de C no suelen ser los mejores en la compilación cruzada estáticamente vinculada.
Pero resulta que hay una excepción.
Ingresar a zig cc
Puede que hayas oído hablar de Zig, un nuevo lenguaje de programación de sistemas que ha estado ganando algo de adopción recientemente. Es rápido, simple y, lo más importante, tiene una gran interoperabilidad con C. Tanto es así que en realidad viene con su propio compilador de C, zig cc.
Pero zig cc no es un compilador de C ordinario. Es un compilador de C que tiene soporte fácil y listo para usar para la compilación cruzada. Como acabamos de ver, la compilación cruzada en C es bastante dolorosa, ya que requiere instalar un compilador para un objetivo específico (o compilarlo desde el código fuente), encontrar versiones de bibliotecas para la plataforma objetivo y escribir mucha magia de banderas de compilador.
Eliminar todas estas preocupaciones prácticamente nos hizo saltar de alegría. zig cc incluso viene con una larga lista de objetivos que maneja de forma nativa, con bibliotecas incluidas, incluyendo, como te imaginarás, todos los objetivos que necesitamos construir.
Debo admitir que había cierto escepticismo sobre usar Zig para construir nuestra base de código. ¿Sería usar Zig y Go y Rust demasiado “hipsterismo” de programador? ¿Nos juzgarían demasiado duro en Hacker News y en Twitter de desarrolladores?
Pero la prueba final es si el código funciona. ¡Y de hecho funcionó! Zig nos permitió construir nuestro sándwich de Go para todas nuestras plataformas compatibles, incluidas las dependencias de C. Zig es lo suficientemente inteligente como para incluir una versión específica de la plataforma de libunwind, por lo que todo lo que tienes que hacer es pasar la bandera -lunwind y simplemente funcionará.
En el lado de Go, tuvimos que pasar algunas banderas para indicar que en lugar de Go vincular todo, queríamos depender de un enlazador externo, es decir, Zig. La combinación mágica aquí fue linkmode external -extldflags="-static".
Con la ayuda de solo una herramienta de cadena de herramientas de otro lenguaje, pudimos enviar nuestro sándwich de Go a nuestros usuarios y continuar nuestro viaje de portabilidad. La primera versión de turbo enviada con el sándwich de Go fue la versión 1.8.6.
¿Por qué tanto esfuerzo?
Esto puede parecer mucha complejidad para acomodar una migración, una nueva cadena de herramientas junto con protobuf no es algo para subestimar, pero nos permitió cumplir nuestro objetivo principal: seguir enviando código a los usuarios. Una reescritura completa habría detenido el lanzamiento de nuevas funciones durante meses y habría corrido el riesgo de acumular código no utilizado. No importa cuántas pruebas se realicen, no importa cuán riguroso sea su sistema de tipos, el código que no se usa es código que está listo para errores. El sándwich de Go aseguró que, a medida que migrábamos el código, cada nueva pieza se usara y validara activamente.