
Published
- 12 min de lectura
Turborepo de Go a Rust, I

Traducido de la entrada de Nicholas Yang, parte del Turborepo Core Team, y Anthony Shew, de Turbo DX en el blog de Vercel.
En una publicación de blog anterior, hablamos sobre por qué estamos migrando Turborepo, el sistema de construcción de alto rendimiento para JavaScript y TypeScript, de Go a Rust. Ahora, hablemos sobre cómo lo estamos haciendo.
Hoy en día, nuestro esfuerzo de migración está en pleno apogeo, moviendo más y más código a Rust. Pero cuando comenzamos, tuvimos que asegurarnos de que la migración fuera factible para que pudiéramos lograrlo. Una migración de un lenguaje a otro no es una tarea pequeña y hay mucha investigación por hacer al principio para asegurarse de que el objetivo final sea alcanzable.
Así es como comenzamos el proceso, validamos nuestra estrategia actual de migración y decidimos migrar Turborepo a Rust.
Migración vs. reescritura completa
Cuando estábamos planeando nuestra migración, consideramos brevemente una reescritura completa desde cero. Pero, al analizar la idea, nos dimos cuenta de que no se ajustaría tan bien a nuestros objetivos como lo haría una migración incremental.
¿Qué es una migración incremental?
La migración incremental mueve el código pieza por pieza, ejecutando código nuevo y antiguo al mismo tiempo. El objetivo para el fragmento de código que se está moviendo es mantener el comportamiento exactamente igual que antes de ser migrado.
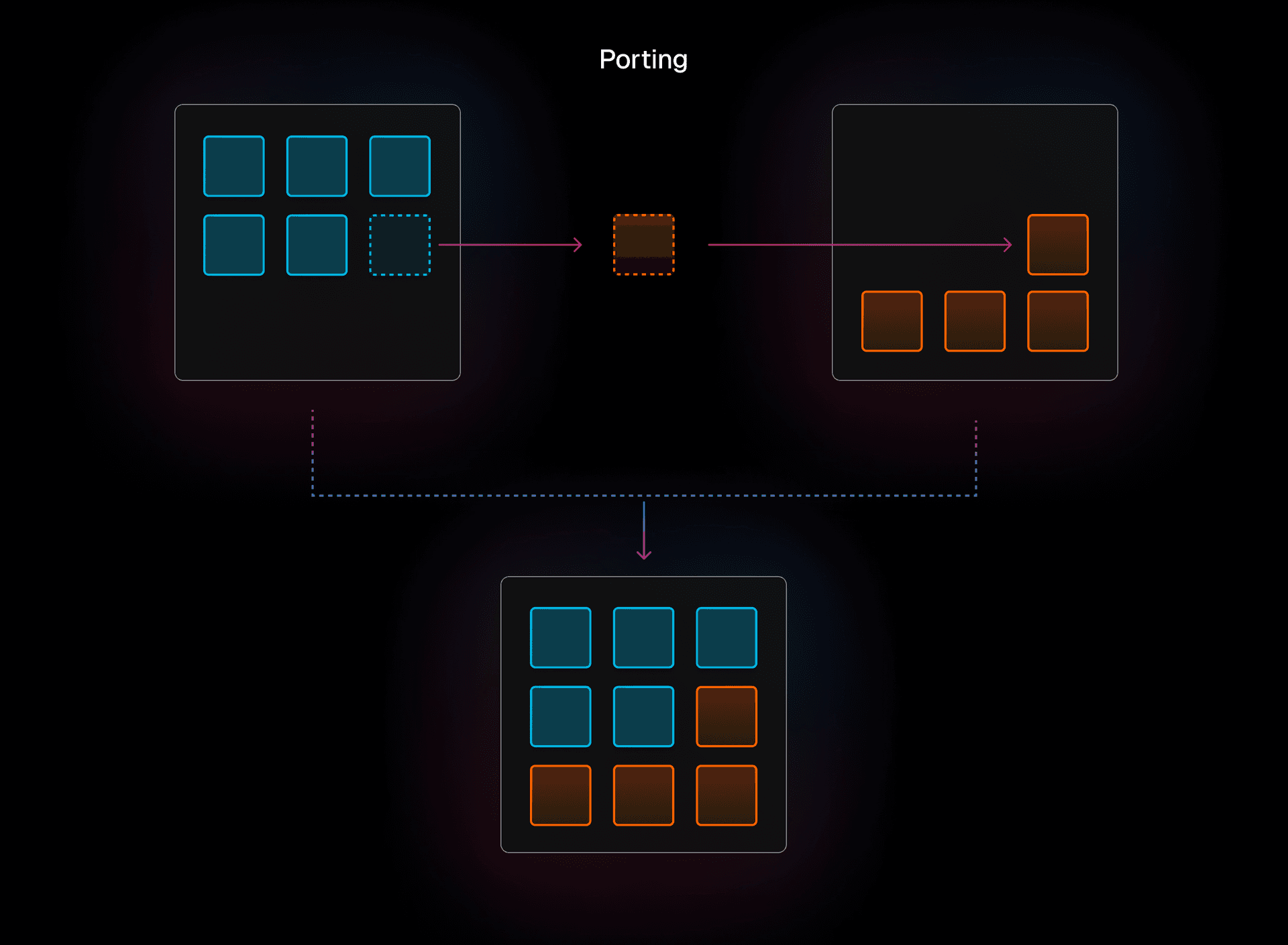
En nuestro caso, esto significa que necesitamos que nuestro código en Go y en Rust interoperen entre sí. Queremos hacer una traducción simple, evitando explícitamente hacer mejoras o cambiar la funcionalidad cuando estamos intercambiando los lenguajes para el fragmento de código. De esta manera, podemos realizar pruebas intensivas en ambos conjuntos de código y completar la migración lo más rápido posible.
¿Por qué no hicimos una reescritura completa?
Las reescrituras completas son muy tentadoras. Son más simples de escribir y lanzar, ya que no necesitas preocuparte por que tu código “antes” y “después” funcionen juntos. También obtienes una pizarra limpia para escribir una versión nueva y mejorada, sin los defectos y la deuda técnica de la iteración anterior. Sin embargo, las reescrituras completas también tienen algunos inconvenientes serios.
Primeramente, una reescritura completa tiende a requerir una parada completa en el lanzamiento de nuevas características. De lo contrario, corres el riesgo de perseguir un objetivo en movimiento mientras el antiguo código crece mientras intentas ponerte al día con tu nuevo código.
Además, una reescritura completa no garantiza una mejor experiencia para el usuario. A menudo, una reescritura resulta menos que perfecta, ya que no es factible que la nueva versión coincida con la antigua, característica por característica, caso por caso. A medida que aumenta la superficie de la reescritura, hay más margen para errores y los usuarios pueden terminar frustrados con cambios disruptivos y características faltantes.
Las reescrituras completas también requieren construir una base de código completamente nueva, que es una gran cantidad de código no utilizado. En nuestra experiencia, el código no utilizado, incluso cuando se verifica con pruebas, puede ser un caldo de cultivo para errores. Queríamos asegurarnos de que cualquier nuevo código Rust se ejerciera adecuadamente mientras avanzábamos en nuestro esfuerzo de migración.
Por qué migrar
Por lo tanto, decidimos migrar Turborepo a Rust en lugar de hacer una reescritura completa.
La migración necesitó algunos compromisos. Tuvimos que introducir una cantidad significativa de complejidad en nuestra base de código, para que pudiéramos interoperar entre Go y Rust. Esta complejidad significó una velocidad de desarrollo más lenta al principio, pero esperamos mejoras en el flujo de trabajo en el futuro, especialmente cuando nuestro esfuerzo de migración haya terminado.
Más importante aún, sabíamos que podríamos seguir lanzando características a los usuarios de Turborepo mientras migrábamos. Considerando todo, determinamos que este era un compromiso razonable y el camino que tomaríamos.
Comenzando la migración
Decidimos comenzar escribiendo una pequeña nueva característica de Turborepo en Rust. De esta manera, podríamos agregar nueva funcionalidad de la hoja de ruta para los usuarios, integrar Rust en nuestro proceso de construcción e interactuar con el código Go existente lo menos posible para reducir nuestra complejidad inicial.
Una vez que hubiéramos sentado estas bases, sabíamos que podríamos migrar lentamente más y más código a Rust con el tiempo.
turbo global
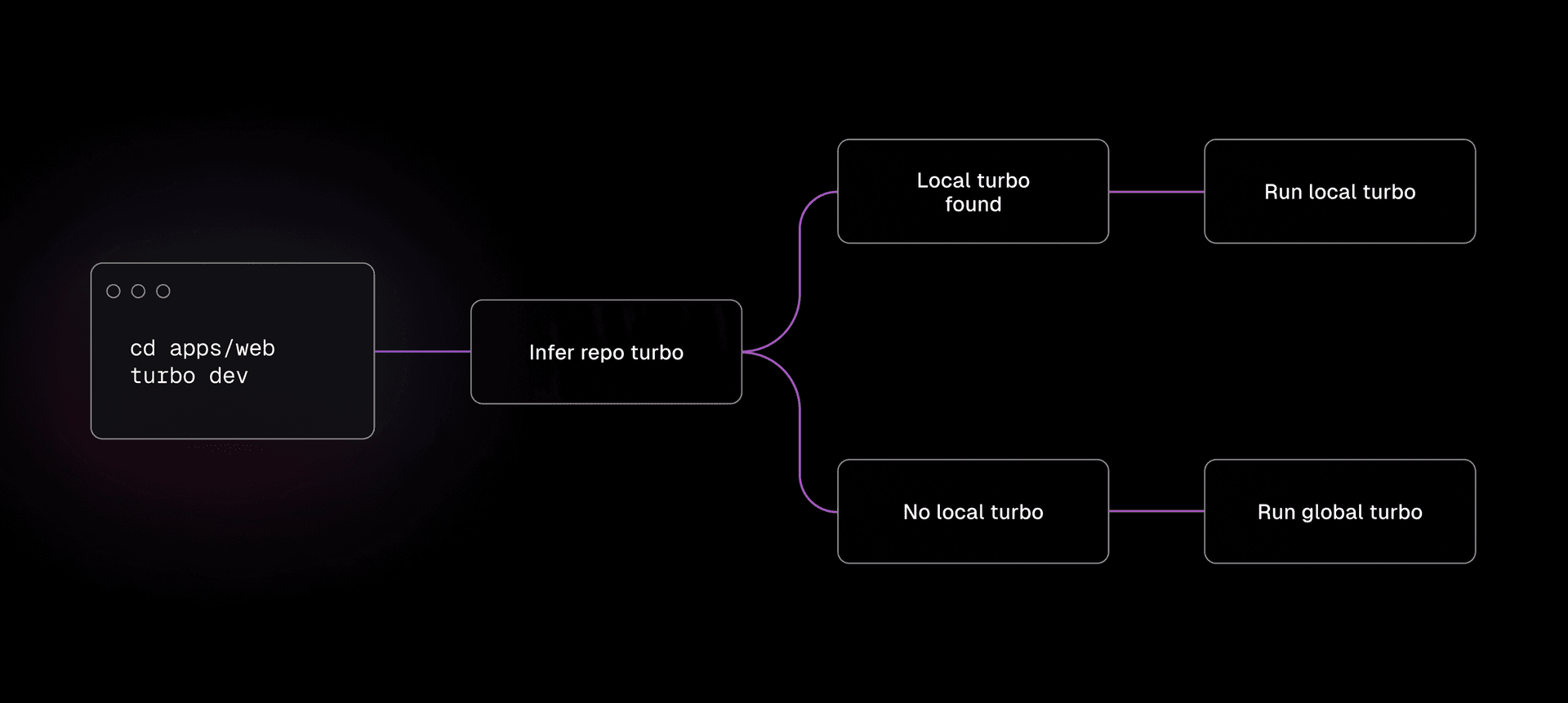
Decidimos que nuestra primera característica en Rust sería turbo global, una característica que permite a los usuarios instalar Turborepo como un comando globalmente disponible en su máquina.
Una instalación global de turbo buscará un programa turbo instalado localmente en el repositorio, lo ejecutará si existe, y de lo contrario, volverá al binario turbo global. De esta manera, puedes ejecutar fácilmente turbo desde cualquier lugar de tu repositorio, pero también mantener una versión específica de turbo fijada en tu package.json.
Esta función se implementa a través de lo que comenzamos a llamar “el refuerzo de Rust”, un poco de código Rust que envuelve el código Go existente. La parte Go se compila a través de CGO como una biblioteca estática de C y luego se enlaza al binario Rust. Afortunadamente, el turbo global solo requería algunas características del resto del código de Turborepo, como leer la configuración y navegar por el sistema de archivos.
Análisis de la línea de comandos
Mientras implementábamos el turbo global, nos dimos cuenta de que necesitábamos analizar algunos argumentos de línea de comandos como --cwd, el argumento para establecer el directorio de trabajo actual de turbo.
Después del turbo global, tenía sentido continuar portando el resto del analizador de argumentos de la interfaz de línea de comandos (CLI) a Rust. Para analizar los argumentos, usamos la biblioteca clap (equivalente de Rust a un paquete npm). clap te permite definir un tipo de datos con los argumentos, anotarlo un poco, y automáticamente creará un analizador.
Con las piezas en su lugar, tuvimos que trabajar en enviar los argumentos desde el punto de entrada de Rust al código Go. Para bien o para mal, C es el estándar para la interfaz de funciones externas (FFI), así que tuvimos que usar C para comunicarnos entre Rust y Go.
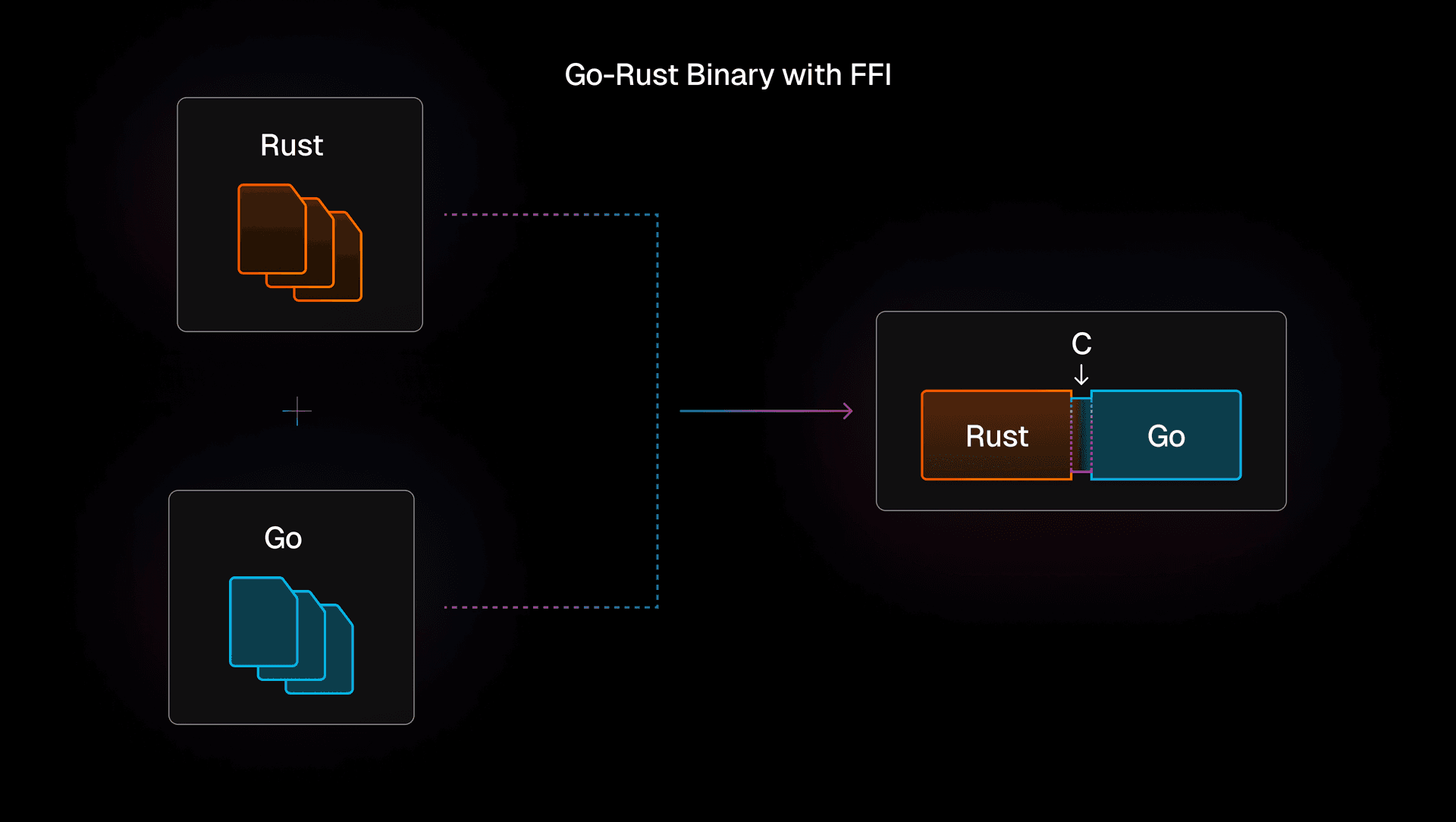
Queríamos evitar tener demasiados tipos en C, ya que no estábamos seguros de poder escribir tipos de C multiplataforma que funcionaran bien tanto con Rust como con Go. En su lugar, decidimos serializar nuestros argumentos a JSON y enviarlos a Go como una cadena. Aunque la serialización JSON tiene cierto costo adicional, sabíamos que la estructura de argumentos solo tendría unos pocos cientos de bytes de tamaño, por lo que el impacto en el rendimiento sería mínimo.
En el lado de Rust, usamos otra biblioteca básica del ecosistema de Rust, serde, que te permite serializar y deserializar datos en varios formatos diferentes, utilizando una mínima anotación. Para el lado de Go, ya estábamos usando JSON en el código, así que fue fácil recibir la cadena JSON y deserializarla en una estructura de Go.
¿Listo para lanzarlo?
Con estas dos características portadas, estábamos listos para lanzar nuestra primera versión híbrida Go-Rust.
Sin embargo, antes de poder lanzar, necesitábamos asegurarnos de que el binario Go-Rust funcionara en todos los diferentes contextos en los que se utiliza Turborepo, como los diferentes sistemas operativos y distribuciones de Linux que admitimos. Mientras probábamos nuestro código, comenzamos a notar algunos problemas en un par de plataformas.
Dificultades en Windows
En Windows, hay dos cadenas de herramientas principales, Microsoft Visual C++ (MSVC) y Minimalist GNU for Windows (MinGW).
Go solo usa MinGW, pero estábamos usando Rust con MSVC. Esto causó algunos problemas en tiempo de ejecución, pero, afortunadamente, la solución fue simple: movimos nuestra cadena de herramientas de Rust a MinGW.
A continuación, tuvimos algunos problemas con las rutas. Windows tiene un par de conceptos de rutas, incluido lo que se llama una ruta de Convención de Nombres Universal (UNC). Cuando le pides a Windows que canonice una ruta (resuelve todos los enlaces simbólicos y normaliza los componentes de la ruta), te da una ruta UNC.
Sin embargo, a pesar del nombre, las rutas UNC no son compatibles en todas partes, ¡a veces ni siquiera por Windows mismo! Esto causó algunos errores donde proporcionábamos una ruta UNC y recibíamos un error de ruta no válida. La solución fue usar una útil crate de Rust llamada dunce que te permite canonizar una ruta y obtener una ruta no UNC, manejando las complejidades de este problema por nosotros.
Alpine Linux
El segundo conjunto de desafíos llegó con Alpine Linux. En Vercel, usamos Alpine, un sistema operativo común para la informática en la nube, para crear contenedores livianos para compilar tus proyectos.
Sin embargo, Alpine no viene con glibc, la implementación de facto de la biblioteca estándar de C. Esto es un problema porque muchos binarios asumen que glibc está instalado y no lo empaquetan ellos mismos. Hay algunas bibliotecas que solucionan este problema usando paquetes como gcompat o libc6-compat, pero no funcionaron para nosotros porque la versión de glibc que requiere Rust era demasiado moderna para nuestros objetivos admitidos. Cuando intentábamos ejecutar el binario, recibíamos errores de que la versión de glibc requerida no estaba disponible.
Como resultado, decidimos compilar Turborepo como un binario completamente estático. Esto significaba que empaquetamos nuestra propia implementación de la biblioteca estándar de C usando musl (ya que no puedes vincular estáticamente glibc debido a problemas de licencia). Esto parece funcionar muy bien tanto para Rust como para Go: Rust te permite configurar la biblioteca estándar de C en el destino (aarch64-unknown-linux-musl vs. aarch64-unknown-linux-gnu) y Go no usa una biblioteca estándar de C de forma predeterminada.
Sin embargo, cuando ejecutábamos este binario enlazado estáticamente, devolvía un fallo de segmentación. ¡Peor aún, cuando lo inspeccionábamos con un depurador, encontrábamos una pila corrupta! Y, aún peor, ¡el fallo de segmentación parecía estar proviniendo del propio tiempo de ejecución de Go!
Después de mucha búsqueda, encontramos una incidencia de GitHub de hace siete años que explicaba que Go no puede compilarse como una biblioteca estática de C con musl. Esto planteó un desafío significativo, ya que Alpine Linux es una plataforma esencial para Turborepo y sus usuarios. Tuvimos que volver a empezar desde cero y descubrir cómo podríamos enviar nuestra combinación de Go y Rust.
Eventualmente, después de mucha más deliberación, encontramos una solución: compilaríamos nuestro código Go y nuestro código Rust como dos binarios separados. El código Rust llamaría al código Go y pasaría los argumentos serializados a JSON a través de la línea de comandos.

Sabíamos que los argumentos eran lo suficientemente pequeños como para ser pasados a través de la línea de comandos sin demasiado impacto en el rendimiento. Y debido a que estábamos utilizando un formato de serialización, los cambios de código eran extremadamente pequeños. Todo lo que tuvimos que hacer fue cambiar la forma en que Rust enviaba la cadena JSON a Go.
Con eso, pudimos lanzar nuestra primera versión híbrida de Go y Rust. La primera versión de turbo que se envió utilizando estas estrategias de compilación fue la versión 1.7.0.
Lo que hemos aprendido
A través de este esfuerzo, hemos aprendido mucho sobre cómo pasar de un lenguaje a otro. Tomemos nota de lo que hemos descubierto.
La serialización es útil para la Interfaz de Programación entre Lenguajes (FFI, por sus siglas en inglés)
Nuestra primera lección es que los formatos de serialización son muy útiles para la interoperabilidad. Al serializar a JSON, un formato con un sólido soporte tanto en Go como en Rust, pudimos minimizar nuestra superficie de FFI y evitar toda una clase de errores entre plataformas y lenguajes. Cuando tuvimos que cambiar de un solo binario vinculado a dos binarios, pudimos hacerlo con relativa facilidad porque nuestra superficie de FFI era tan pequeña.
El compromiso aquí es que la serialización y deserialización son lentas. Solo puedes depender de esta técnica si sabes que tus cargas serializadas serán pequeñas o si no te importa el impacto en el rendimiento para tu caso de uso.
La migración requiere preparación
La segunda lección es que la migración incremental es factible pero requiere mucha prueba y estrategia cuidadosa. Nos encontramos con varios errores complicados y capturamos estos problemas a través de muchas pruebas automatizadas y manuales. Puedes revisar nuestras suites de pruebas (y las de Turbopack) en nuestros flujos de trabajo de GitHub.
Las pruebas también son extremadamente importantes para determinar el comportamiento de tu código, ya sea en los casos límite exactos del análisis de la línea de comandos, o el orden en que se carga la configuración. Estos detalles exactos no son tan cruciales cuando estás escribiendo tu primera implementación, pero son absolutamente fundamentales para evitar cambios que rompan durante una migración o reescritura. Deberías intentar escribir pruebas antes de comenzar a migrar el código, para que tengas una especificación conocida con la que trabajar.
La compatibilidad cruzada es difícil
La tercera lección es que la ingeniería de lanzamientos entre plataformas y lenguajes es extremadamente desafiante. Cada plataforma, lenguaje y compilador tienen sus propias peculiaridades que pueden dificultar la interoperabilidad y, cuanto más cosas tengas funcionando juntas, más oportunidades tendrás de una nueva complicación.
La migración vale la pena para nosotros
Finalmente, aunque migrar de Go a Rust ha sido desafiante, ha demostrado ser la elección correcta para nosotros estratégicamente. Incluso con nuestro esfuerzo de migración en marcha, hemos podido lanzar nuevas características, manejar errores en la funcionalidad existente y seguir ayudando a nuestros usuarios mientras migramos. Ha requerido algunas depuraciones extraordinariamente complicadas, una planificación cuidadosa y pruebas rigurosas, pero creemos que ha valido la pena.
Prueba (la versión porteada de) Turborepo
Esta semana, Turborepo ahorró 5,742 horas de tiempo para los ingenieros de productos y las máquinas de CI en Vercel. Si quieres probar la misma tecnología en solo unos minutos, echa un vistazo a nuestro artículo sobre cómo puedes empezar con el Vercel Remote Cache.