
Published
- 11 min de lectura
Turborepo de Go a Rust, III

Traducido de la entrada de Nicholas Yang, parte del Turborepo Core Team y Anthony Shew, de Turbo DX, en el blog de Vercel.
Hemos terminado de trasladar Turborepo, el sistema de construcción de alto rendimiento en JavaScript y TypeScript, de Go a Rust. Esto sienta las bases para un mejor rendimiento, una mayor estabilidad y potentes nuevas características.

Así es cómo terminamos este port y lanzado la primera version totalmente hecha en Rust de turbo.
Desde la última vez
Después de considerar estas opciones, optamos por construir lo que llamamos el “sándwich de Rust-Go-Rust” o el “sándwich de Go” para abreviar. Consiste en un binario Rust que llama a un binario Go, que a su vez llama a bibliotecas Rust que están vinculadas estáticamente al binario Go. Esto nos permite dividir el código de ejecución y poda entre los dos lenguajes y trasladar las dependencias individuales. De esta manera, pudimos abordar la ejecución y la poda de forma incremental, lo que permitió una mejor prueba y depuración durante la migración.
Nicholas Yang -> https://vercel.com/blog/how-we-continued-porting-turborepo-to-rust
Al final de nuestro artículo anterior, habíamos completado el “sándwich de Rust-Go-Rust”, o “sándwich de Go” para abreviar, y lo habíamos enviado con ayuda de Zig. El sándwich nos permitió seguir trasladando incrementalmente piezas individuales de Turborepo. Desde entonces, trasladamos más componentes como:
- Hashing de archivos: el mecanismo de Turborepo para crear una huella digital del contenido en tu repositorio para que las comparaciones de caché sean rápidas.
- Análisis de lockfile: si las dependencias instaladas en tu repositorio cambian, Turborepo necesita tenerlo en cuenta.
- Verificación de firma de caché: añade tu propia clave privada a los hashes de archivos para obtener una capa adicional de seguridad.
Alcanzando los límites del sándwich de Go
Sin embargo, al completar estos componentes, empezamos a alcanzar el límite de lo que el sándwich podía manejar. Por ejemplo, mezclar código asíncrono y multi-threaded entre lenguajes no iba a ser viable. El sándwich Go nos llevó hasta este punto pero, con tanto de nuestro código ahora trasladado a Rust, el sándwich había cumplido su propósito.
Por lo tanto, decidimos construir lo que llamamos “el esquema de ejecución”, una versión completamente en Rust de nuestro comando run con la mayor parte de la funcionalidad simulada (reemplazada con una versión falsa y simple). Lo protegimos detrás de una bandera de características, para poder construirlo para nuestras versiones locales pero no enviarlo a los usuarios todavía.
Era hora de completar el cambio a todo Rust.
Construyendo el gráfico de paquetes
La primera gran pieza que añadimos a nuestro esquema de ejecución fue el gráfico de paquetes. El gráfico de paquetes es una estructura de datos de grafo de todos los paquetes en tu Turborepo, donde los nodos del grafo son tus paquetes y las aristas son las relaciones de dependencia entre ellos. Esto nos permite comprender profundamente tu monorepo y cachear el trabajo para que nunca lo hagas dos veces.

Cuando trasladamos el gráfico de paquetes, notamos que las características de Rust nos permitían construir tipos mejores que modelaban más precisamente tu repositorio. Por ejemplo, en Go, designamos la raíz del espacio de trabajo (donde reside tu archivo de bloqueo) con una cadena mágica (//). Los nombres de los paquetes se almacenaban como cadenas, así que para comprobar la raíz del espacio de trabajo, verificábamos si el nombre era igual a //.
En Rust, pudimos modelar esto como un enum. Los enums en Rust te permiten crear un tipo que podría ser uno de varios valores. En este caso, nuestro nombre de paquete podría ser el paquete raíz o un paquete diferente con un nombre. Podemos modelarlo así:
enum PackageName {
Root,
Other(String)
}No solo es más eficiente, también garantiza la corrección. Cada vez que se utiliza un nombre de paquete en el código de Rust, tenemos que manejar el caso de la raíz del espacio de trabajo o el compilador se quejará. En Go, era mucho más tentador usar cadenas y manejar los casos de manera ad hoc, dejando más margen para el error.
El comando prune
Con el gráfico de paquetes completado, estábamos listos para abordar la versión completamente en Rust de prune. El comando de poda te permite eliminar todo de tu Turborepo excepto un paquete individual y sus dependencias. Si ejecutas turbo prune web-app, crearás una carpeta out con solo el código y las dependencias para tu aplicación web.
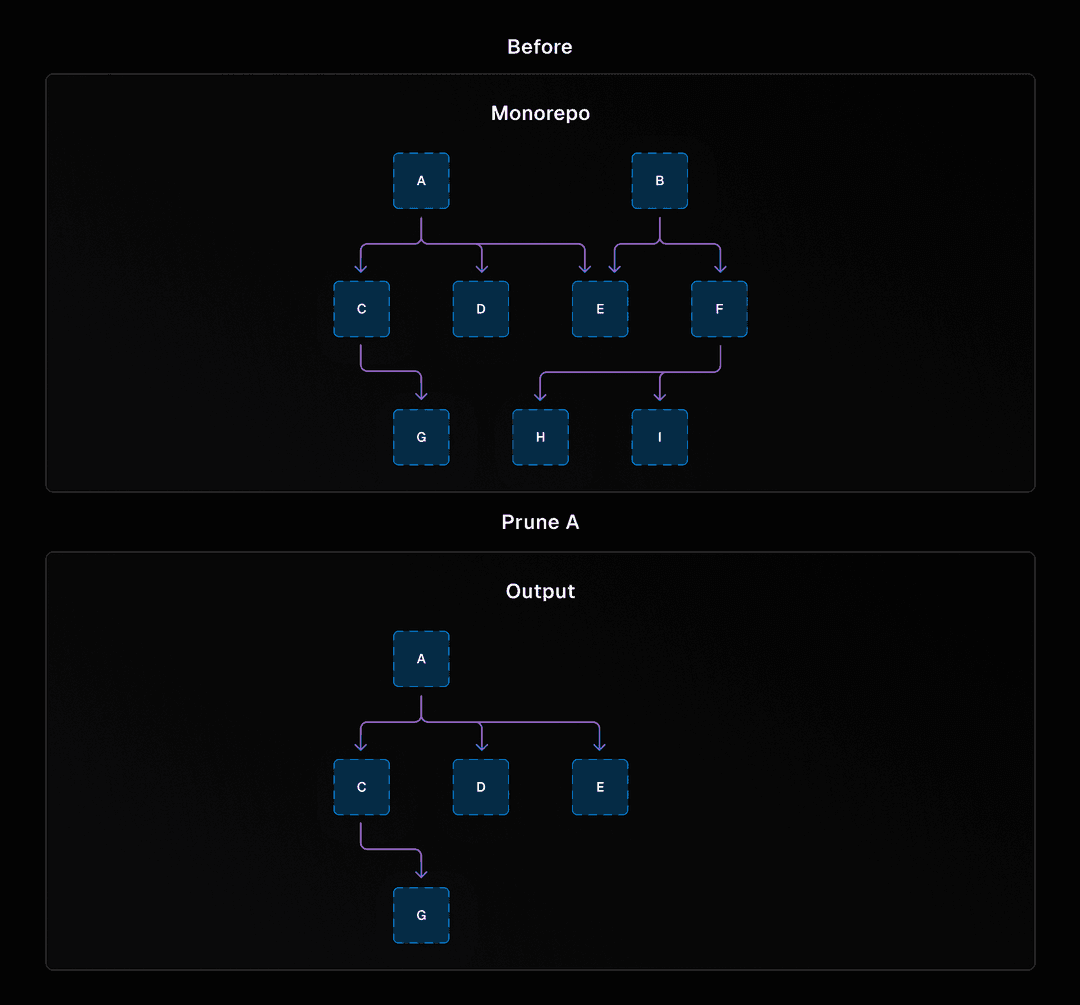
Un gráfico que muestra un monorepositorio completo con paquetes abstractos y otro gráfico dirigido que muestra un subconjunto del monorepositorio después de ejecutar turbo prune en el monorepositorio.
Esto es particularmente útil para construir imágenes Docker donde te gustaría mantener el tamaño de tu imagen pequeño. También estamos emocionados por construir funcionalidades sobre este comando, como usar archivos de bloqueo podados para instalar solo las dependencias de la aplicación que te interesan.
Afortunadamente, ya habíamos trasladado la mayor parte del código del archivo de bloqueo a través del sándwich, así que solo fue cuestión de conectar nuestras piezas existentes. Si observas la pull request, pudimos fusionar la poda con relativamente pocas iteraciones. Esto se debió a que el sándwich Go nos había permitido construir las dependencias de Rust y probarlas en nuestro código Go existente.
Tareas de hashing para el comando run
Una vez que completamos prune, llegamos a una de las piezas centrales de Turborepo: el hashing. El hashing es lo que permite a Turborepo determinar si ya has ejecutado una tarea.
¿Qué es el hashing?
Un algoritmo de hashing toma algunos datos y produce un único valor, conocido como un hash. Con un alto grado de probabilidad, estos hashes serán únicos para los datos de entrada. Terminas con una huella digital de tus datos que se puede comparar rápidamente con otras huellas digitales.
Esto es ventajoso ya que los hashes se pueden crear rápidamente y son fáciles de comparar entre sí. El hashing aparece en muchos lugares diferentes, ya sea mapeando claves a valores en un mapa hash, almacenando eficientemente diferentes versiones de tu código en git o almacenando contraseñas de forma segura.
Hashing en Turborepo
Usamos hashing para implementar nuestra caché. Cuando usas turbo run, Turborepo toma todas las diferentes entradas que intervienen en la construcción de tus paquetes, como el código fuente, las variables de entorno y las dependencias, y las envía a través del algoritmo de hashing.

Lo hacemos a dos niveles:
- A nivel global, producimos un hash que determina si has cambiado algo que afecta a todo el repositorio.
- También creamos muchos hashes de tarea para determinar si has cambiado algo para una tarea específica. El hash global se incluye en el cálculo de estos hashes, por lo que potencialmente puede cambiar todos ellos.
Para utilizar estos hashes para tu caché, almacenamos las salidas de tu tarea en un archivo tar, un tipo de archivo especial que comprime una carpeta entera en un solo archivo. Almacenamos ese archivo tanto en el sistema de archivos local como en la Vercel Remote Cache, indexado por este hash de tarea.
Cuando llega el momento de ejecutar una tarea, primero producimos este hash de tarea y comprobamos si está en el sistema de archivos o en la Caché Remota. Si está, restauramos las salidas de la tarea en milisegundos. De lo contrario, ejecutamos la tarea y almacenamos las salidas en la caché para la próxima vez.
Asegurando la estabilidad del hash mientras se traslada run y prune
Cuando se trataba de trasladar el código de hash, queríamos que los hashes permanecieran iguales entre Rust y Go. No tiene sentido que los usuarios de Turborepo pierdan la caché solo porque el lenguaje que se usó para escribir la herramienta cambió bajo la superficie. Tuvimos que priorizar la estabilidad.
Para mantener los hashes estables, recurrimos a Capnproto, un formato de serialización multiplataforma y multiidioma que está definido byte a byte. ¡Además, capnproto tiene un gran soporte para Go y Rust!
Después de refactorizar nuestro código de hashing para usar Capnproto tanto para Rust como para Go, configuramos nuestra CI para ejecutar nuestras tareas en ambos caminos de código y comparar los dos hashes. Si alguna vez divergían, nuestra CI fallaría y necesitaríamos hacer algunas correcciones.
Alcanzando la línea de meta
Cuando comenzamos a ejecutar el código de comparación de hashes, no nos sorprendió encontrar que teníamos errores. Algunos errores eran menores, como asegurar que los valores null contribuyan al hash correctamente. Sin embargo, algunos errores eran más fundamentales, como detectar qué paquetes habían cambiado o manejar la bandera --filter para que solo puedas hacer el trabajo que estás buscando.
Nos alegró ver que nuestro enfoque dio sus frutos aquí, ya que estos habrían sido errores increíblemente difíciles de encontrar de otra manera. Al final, pudimos validar que nuestro código de hashing en Rust funcionaba y coincidía con el comportamiento de Go.
En general, este enfoque realmente valió la pena para nosotros. Encontramos muchos errores que de otra manera habríamos tenido dificultades para encontrar. Pudimos validar que nuestro código funcionaba y coincidía con el comportamiento de Go.
Probando nuestro propio camino hacia un lanzamiento
En este punto, habíamos trasladado suficiente código para ejecutar nuestras tareas en nuestra propia CI detrás de una bandera —experimental-rust-codepath. Empezamos a ejecutar nuestras pruebas de integración en el camino de código de Rust y a resolver los fallos de prueba hasta que coincidimos con la versión de Go, línea de registro por línea de registro, salida por salida. Una vez que todas nuestras pruebas pasaron, publicamos una versión canary y la utilizamos en el monorepo interno de Vercel. ¡Una vez que alcanzamos 72 horas sin errores reportados, lanzamos Turborepo 1.11!
Lo que aprendimos
Mirando hacia atrás, el traslado fue un gran éxito. Logramos trasladar alrededor de 70k líneas de código de Go a Rust en 15 meses con una interrupción mínima para los usuarios. Nuestras estrategias de traslado, como el Rust shim y el Go sandwich, nos permitieron trasladar incrementalmente código durante el mayor tiempo posible.
Dicho esto, probablemente habría algunas cosas que habríamos hecho de manera diferente con nuestro nuevo conocimiento:
- Invertir en un único formato de serialización desde el principio. Adoptamos un enfoque iterativo, comenzando con JSON, luego usando Protocol Buffers, y finalmente terminando con Capnproto. Al final, nos dimos cuenta de que Capnproto nos habría servido mejor desde el principio. Solo descubrimos su valor para nuestro caso cerca del final.
- Lanzar cada estrategia de traslado más rápido. Esperamos un poco demasiado tiempo para descubrir nuestra estrategia de lanzamiento para el Rust shim y el Go sandwich. Esto significaba que había momentos en los que habíamos trasladado código que no podíamos enviar a los usuarios debido a errores en la gestión de lanzamientos. Si hubiéramos lanzado una versión absolutamente mínima de cada estrategia de traslado lo antes posible, no habríamos tenido estos problemas.
- Darse cuenta de la importancia de la calidad del código antes del traslado. En general, nuestro código de Go estaba en buen estado con pruebas exhaustivas y una arquitectura bastante sencilla. Sin embargo, llegamos pensando que podríamos refactorizar mientras trasladábamos, pero resultó que no era el caso. Mirando hacia atrás, podríamos haber trasladado más rápido si hubiéramos mejorado nuestra historia de pruebas y eliminado algo de redundancia del código de Go antes de comenzar.
- Especificar completamente los comportamientos principales de Turborepo como la expansión de globs, la observación de archivos y el hashing. Descubrimos muchos casos durante el traslado donde no estaba claro si algún comportamiento en estas áreas era accidental o intencional en el código de Go. Habría ayudado a descubrir estos escenarios no documentados y no probados que ahora están codificados en Rust. También podríamos haber solidificado nuestro soporte multiplataforma, específicamente para nuestras pruebas en Windows.
El futuro de Turbo
Estamos increíblemente emocionados por el futuro que Rust traerá a los usuarios de Turborepo y Turbopack. Estamos descubriendo nuevas oportunidades cada día para crear excelentes características, garantizar una mayor estabilidad de tu base de código y hacer que tu CI sea más rápido que nunca.
También estamos ansiosos por integrar Turborepo aún más en la Vercel Developer Experience Platform. Con el reciente lanzamiento de Conformance y Code Owners, las organizaciones de ingeniería están enviando código de mayor calidad más rápido, incluso a medida que su base de código escala.
